buddy和slab算法
buddy
内核使用struct page结构体描述每个物理页,也叫页框。
内核在很多情况下,需要申请连续的页框,而且数量不定,比如4个、5个、9个等。
Linux把所有空闲的页框分组为11个块链表,每个链表上的页框是固定的。在第i条链表中每个页框都包含2的i次方个连续页。
系统每个页框块的第一个页框的物理地址是该块大小的整数倍。例如大小为16个页框的块,其起始地址是10*2^12的倍数
页框操作
1 | // 分配2^order个连续的物理页,并返回一个指针,指向第一个页的page结构体 |
Buddy提供了以page为单位的内存分配接口,这对内核来说颗粒度还太大了,所以需要一种新的机制,将page拆分为更小的单位来管理。
slab
slab实现了内存的分配和管理
slab层把不同的对象划分为高速缓存组(cache),其中每个高速缓存都存放不同类型的对象。每个对象对应一个高速缓存(cache)。例如一个高速缓存存放task_struct结构体,而另外一个高速缓存存放struct inode结构体。slab由一个或者多个物理页组成,每个高速缓存由多个slab组成。
slab分配器的基本思想是,先利用页面分配器分配出单个或者一组连续的物理页面,然后在此基础上将整块页面分割成多个相等的小内存单元,以满足小内存空间分配的需要。当然,为了有效的管理这些小的内存单元并保证极高的内存使用速度和效率。
在内核中,经常会使用一些链表,链表中会申请许多相同结构的结构体,比如文件对象,进程对象等等,如果申请比较频繁,那么为它们建立一个内存池,内存池中都是相同结构的结构体,当想申请这种结构体时,直接从这种内存池中取一个结构体出来,是有用且速度极快的。一个物理页就可以作用这种内存池的载体,进而进行充分利用,减少了内部碎片的产生。
所以,Slab 相当于内存池思想,且是为了解决内碎片而产生的,slab的核心思想是以对象的观点管理内存。
所谓的对象就是存放一组数据结构的内存区,为便于理解可把对象看作内核中的数据结构(例如:task_struct,file_struct 等)。
相同类型的对象归为一类,每当要申请这样一个对象时,slab分配器就从一个slab列表中分配一个这样大小的单元出去,而当要释放时,将其重新保存在该列表中,而不是直接返回给伙伴系统,从而避免内部碎片。
slab为这样的对象创建一个cache,即缓存。每个cache所占的内存区又被划分多个slab,每个 slab是由一个或多个连续的页框组成。每个页框中包含若干个对象,既有已经分配的对象,也包含空闲的对象。
尽管英文中使用了Cache这个词,但实际上指的是内存中的区域,而不是指硬件高速缓存
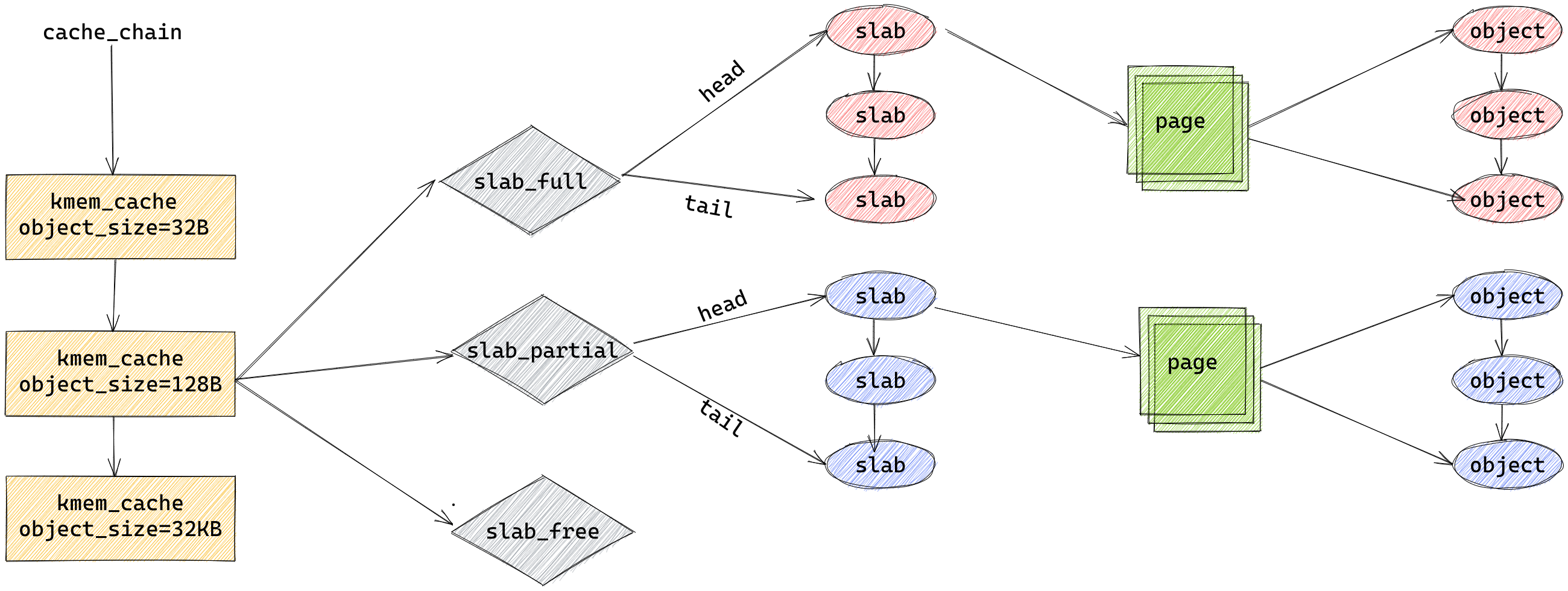
最高层是 cache_chain,这是一个 slab 缓存的链接列表。可以用来查找最适合所需要的分配大小的缓存(遍历列表)
cache_chain 的每个元素都是一个 kmem_cache 结构的引用(称为一个 cache)。它定义了一个要管理的给定大小的对象池。
kmem_cache: 内存池
slab:内存池从系统申请内存的基本单位
object:内存池提供的内存的单位
每个缓存(kmem_cache)都包含了一个 slabs 列表,这是一段连续的内存块(通常都是页面)
其中每个kmem_cache有三条链表
slabs_full:所有对象已分配
slabs_partial:部分对象已分配
slabs_free:对象未分配
查看slab高速缓存分配
1 | $ cat /proc/slabinfo |
slab机制要解决的问题
- 减少伙伴算法在分配小块连续内存时所产生的碎片
- 将频繁使用的对象缓存起来,减少分配、初始化和释放对象的时间开销
- 通过着色技术调整对象以更好的使用硬件高速缓存
slab操作函数
1 | // 创建高速缓存 name:高速缓存名 size:大小 align:对齐大小 |
总结
| vmalloc/vfree | 虚拟连续,物理不定 | vmalloc区限制大小 | 页VMALLOC区 | 可能睡眠,不能从中断上下文中调用。VMALLOC区域vmalloc_start~vmalloc_end之间,vmalloc比kmalloc慢,适用于分配大内存 | |
|---|---|---|---|---|---|
| slab | kmalloc/kcalloc/krealloc/kfree | 物理连续 | 64B-4MB(随slab而变) | 2^order字节Normal区域 | 大小有限,不如vmalloc/malloc大。最大/最小值由KMALLOC_MIN_SIZE/KMALLOC_SHIFT_MAX,对应64B、4MB。从/proc/slabinfo中的kmalloc-xxx中分配,建立在kmem_cache_create基础之上 |
| slab | kmem_cache_create | 物理连续 | 64B-4MB | 字节大小,需对齐,Normal区域 | 便于固定大小数据的频繁分配和释放,分配时从缓存池中获取地址,释放时也不一定真正释放内存。通过slab进行管理 |
| buddy | __get_free_page/__get_free_pages | 物理连续 | 4MB(1024页) | 页,Normal区域 | __get_free_pages基于alloc_pages,但是限定不能使用HIGHMEM |
| buddy | alloc_page/alloc_pages/free_pages | 物理连续 | 4MB | 页,Normal区域/Vmalloc都可 | CONFIG_FORCE_MAX_ZONEORDER定义了最大页面数2^11,一次能分配到的最大页面数为1024 |


