Redis数据结构-跳跃表
跳跃表
如果一个有序集合包含的元素数量比较多,又或者有序集合中的元素成员是比较长的自复制,Redis会使用跳跃表来做有序集合的底层实现。
跳跃表的实现
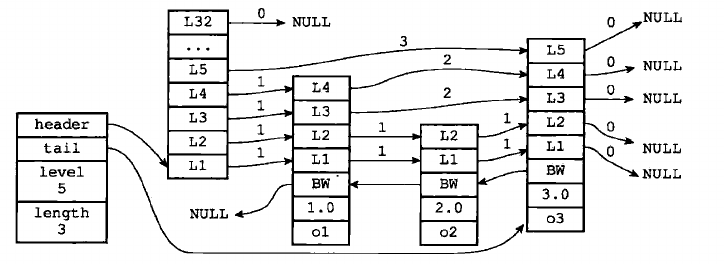
左边是zskiplist结构:
- header:指向跳跃表的头结点
- tail: 指向跳跃表的尾节点
- level: 记录目前跳跃表内,层数最大的那个节点层数(表头节点不计算在内)
- length: 记录跳跃表的长度,跳跃表目前包含的节点数量(表头节点不计算在内)
右边为四个zskiplistNode结构:
- 层(level):节点中用L1、L2、L3等字样标记节点的各层,L1表示第一层,L2表示第二层,以此类推。每个层有带有两个属性:前进指针和跨度。前进指针用于访问位于表尾方向的其他节点,而跨度则记录了前进指针所指向的节点和当前节点的距离。
- 后退(backward)指针:节点中用BW字样标记节点的后退指针,它指向位于当前节点的前一个节点。后退指针在程序从表尾向表头遍历时使用。
- 分值(score):各个节点中的1.0、2.0和3.0是节点保存的分值。在跳跃表中,节点按各自所保存的分值从大到小排序
- 成员对象(obj): 各个节点中的o1、o2、o3节点所保存的成员对象
跳跃表节点
redis/zskiplistNode结构定义
1 | /* |
层
跳跃表节点的level数组可以包含多个元素,每个元素都包含一个指向其他节点的指针,程序可以通过这些层来加快访问其他节点的速度,一般来说,层数越多,访问其他节点的速度越快
每次创建一个新的跳跃表节点的时候,程序都根据幂次定律(power law,越大的数出现的概率越小)随机生成一个介于1和32之间的值作为level数组的大小,这个大小就是层的”高度“
前进指针
每个层都有一个指向表尾方向的前进指针,用于从表头向表尾方向访问节点。(虚线)
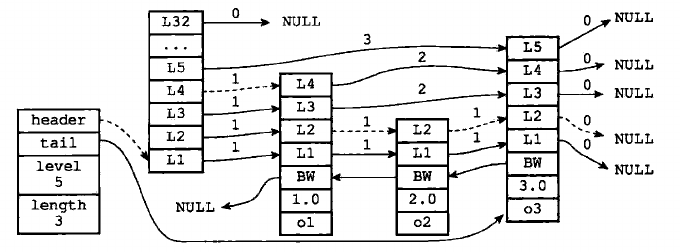
- 迭代程序首先访问跳跃表的第一个节点(表头),然后从第四层的前进指针移动到表中的第二个节点。
- 在第二个节点时,程序沿着第二层的前进指针移动到表中的第三个节点
- 在第三个节点时,程序沿着第二层的前进指针移动到表中的第四个节点
- 当程序再次沿着第四个节点的前进指针移动时,它碰到了一个NULL,程序知道这时已经到达跳跃表表尾,于是结束了这次遍历
跨度
层的跨度用于记录两个节点之间的距离
- 两个节点之间跨度越大,它们距离就越远
- 指向NULL的所有前进指针的跨度都为0,因为它们没有连向任何节点
跨度实际上时用来计算排位的:在查找某个节点的过程中,将沿途访问过的所有层的跨度累计起来得到的结果就是目标节点在跳跃表中的排位。
后退指针
节点的后退指针用表表尾向表头方向访问节点
分值和成员
分值属性是一个double类型的浮点数,跳跃表中的所有节点都按分值从小到大来排序
节点的成员对象是一个指针,它指向一个字符对象,而字符串对象则保存这一个SDS值。
在同一个跳跃表中,各个节点保存的成员对象必须时唯一的,但是多个节点保存的分值确可以是相同的,分值相同的节点按照成员对象在字典序中的大小来进行排序,成员对象较小的节点会排在前面,而成员比较大的节点会排在后面
跳跃表
zskiplist结构定义如下:
1 | /* |
header和tail指针分别指向跳跃表的表头和表尾
通过使用length属性来记录节点的数量。
level属性则用于在O(1)复杂度内获取跳跃表中层高最大的那个节点的层数量。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Ansore!


